Meta has released V-JEPA 2, an advanced AI system that learns from video, in a strategic push to give robots a form of physical common sense. The company announced on June 11 that the open-source “world model” is designed to understand and predict real-world interactions, a critical step toward building more capable and adaptive intelligent agents.
This move positions Meta directly against rivals like Google and other specialized labs in the increasingly competitive race to create embodied AI. By building an internal simulation of reality, these models allow an AI to “think” before it acts, planning complex tasks in a more human-like way. For Meta, the project is a key part of its long-term vision for advanced machine intelligence, with potential applications ranging from industrial robotics to the augmented reality glasses the company has long been developing.
The V-JEPA 2 model represents a significant evolution from its predecessor V-JEPA. While that initial version established the core concept of learning from video, this new 1.2 billion-parameter system is specifically enhanced for practical planning and control, aiming to bridge the gap between digital intelligence and the physical world.
What Are World Models?
At the core of Meta’s strategy is the concept of a “world model,” a type of generative AI system that learns internal representations of an environment, including its physics and spatial dynamics. Unlike large language models that predict the next word in a sentence, world models attempt to predict future states of the world itself. A world model observes its surroundings and anticipates what might happen next, a far more complex task than text-based prediction.
This capability allows machines to simulate potential actions and their consequences internally before attempting them in reality. As Juan Bernabé-Moreno, Director of IBM Research in Europe, explained, “World models allow machines to plan movements and interactions in simulated spaces, often called ‘digital twins,’ before attempting them in the physical world. This dramatically reduces costly trial-and-error, mitigates safety risks and accelerates learning for tasks such as industrial assembly, warehouse logistics or service-oriented robotics.”
This dramatically accelerates learning and improves safety, paving the way for robots that can navigate unpredictable human environments.
Inside V-JEPA 2: How It Learns
V-JEPA 2’s intelligence is forged in a two-stage training process. First, it builds a foundational understanding of the world by analyzing a massive dataset of over one million hours of video and one million images.
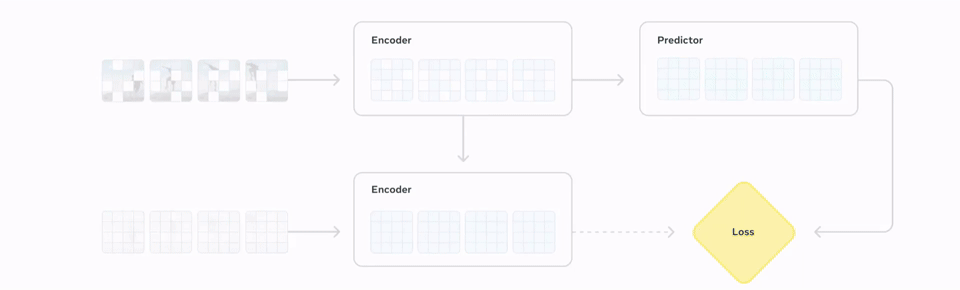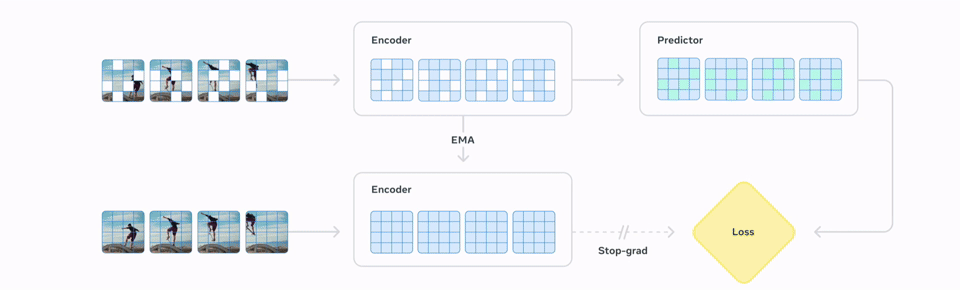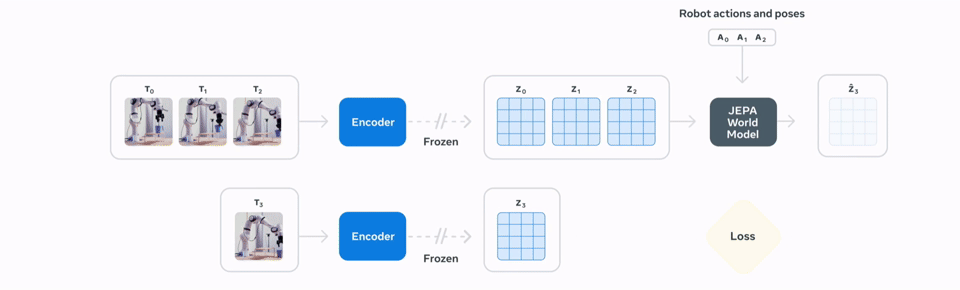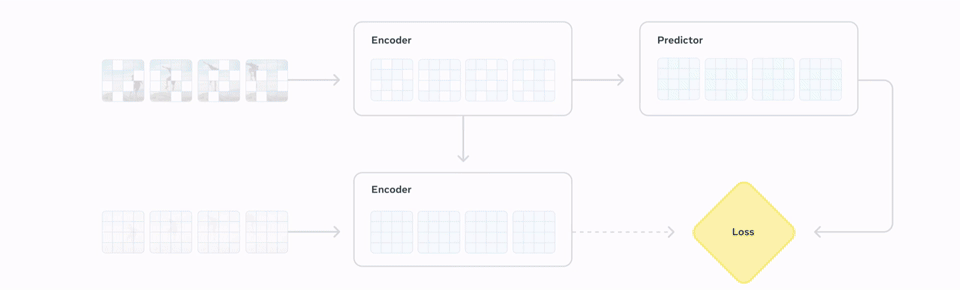
Its architecture, known as a Joint Embedding Predictive Architecture (JEPA), learns by predicting missing or masked-out portions of video in an abstract, conceptual space rather than trying to reconstruct every pixel. This efficiency allows the model to focus on learning high-level concepts about object interactions and motion.
The second stage makes the model useful for robotics. Here, it is fine-tuned with action-conditioned data, using just 62 hours of video and control inputs from the open-source DROID dataset. This teaches the model to connect specific actions to their physical outcomes, resulting in a system that, according to Meta, can be used for “zero-shot robot planning to interact with unfamiliar objects in new environments.”
However, a technical analysis of the first V-JEPA noted that its reliance on very short video clips could limit its ability to understand complex, long-term interactions, a challenge that more advanced world models will need to overcome.
A Crowded Field of Physical Intelligence
Meta’s announcement does not happen in a vacuum. The push to create foundational models for robotics is a key battleground for major tech labs. In March Google DeepMind unveiled its Gemini Robotics models, which similarly integrate vision, language, and action to enable robots to learn with minimal training.
The competitive landscape for embodied AI, as outlined in a survey on ResearchGate, also includes specialized players like Figure AI with its Helix model, Microsoft’s Magma AI, and numerous university efforts.
A critical complementary technology is hyper-realistic simulation. Platforms like the Genesis AI Simulator can rapidly simulate physical environments which are essential for training these models safely and efficiently.
Jim Fan, a researcher involved with the project, vividly described its power: “One hour of compute time gives a robot 10 years of training experience. That’s how Neo was able to learn martial arts in a blink of an eye in the Matrix Dojo.” This highlights the industry-wide focus on overcoming the data bottleneck required to train AI for the near-infinite variations of the physical world.
An Open Approach to a Hard Problem
True to its recent strategy in AI, Meta is releasing V-JEPA 2 and its associated tools as open-source assets. The model’s code is available on GitHub, with checkpoints accessible on Hugging Face. By making the technology widely available, Meta hopes to foster a community that can accelerate progress. However, developers looking for easy integration may face hurdles, as community discussions on GitHub indicate there is currently no dedicated, user-friendly API.
To spur research, Meta has also released three new benchmarks designed to rigorously test how well AI models reason about physics. In its announcement, Meta noted a significant performance gap between humans and even top models on these tasks, highlighting a clear direction for needed improvement.
Progress against these benchmarks can be tracked on a public Hugging Face Leaderboard for physical learning, providing a transparent measure of how close the field is to achieving true physical intelligence.
Meta’s open strategy, combined with the public benchmarking of its models’ limitations, underscores the immense difficulty of the task ahead. While V-JEPA 2 is a significant step, it also illuminates the long road toward creating the kind of advanced machine intelligence that can seamlessly navigate and interact with our complex physical world.